

これまでの記事はこちら

- 1 なぜ「精度が出たモデル」はそのままでは使えないのか
- 2 なぜアンサンブルが必要なのか
- 3 1.2 RandomForest × LightGBM の役割分担
- 4 重み 0.6 : 0.4 の意味
- 5 H間スケール補正の考え方(3・5・10日予測)
- 6 なぜ地平ごとにモデルを分けるのか
- 7 H間スケール補正とは何か
- 8 Hブレンディングの思想
- 9 なぜ通常のCV(Cross Validation:交差検証)は使えないのか
- 10 ローリング原点CVとは
- 11 ローリング原点CVの落とし穴
- 12 エンバーゴの意味
- 13 ネストCVの重要性
- 14 検証で見るべきは「平均」ではない
- 15 MAEとは
- 16 MAPEの意味と注意点
- 17 MAE / ATR(Average True Range) が重要な理由
- 18 HitRateをどう解釈するか
- 19 モデルは「予言」ではなく「判断材料」
- 20 まとめ
なぜ「精度が出たモデル」はそのままでは使えないのか
機械学習で株価予測に取り組むと、多くの人が次の壁にぶつかります。
「CVの数値は良いのに、実運用ではうまくいかない」
これは珍しい話ではありません。
その最大の原因は、
- モデル構造は理解している
- 特徴量もそれなりに作った
- だが 設計思想(アンサンブル・検証・指標解釈)が弱い
という状態にあります。
本記事では
- アンサンブル設計の考え方
- 検証法(ローリング原点CV)の落とし穴と正解
- MAE / MAPE をどう「運用判断」に落とすか
を、初学者でも理解できるレベルから、実運用レベルまで解説します。
なぜアンサンブルが必要なのか
まず大前提として、
単一モデルで株価を安定して当て続けることはほぼ不可能
です。
理由は明確で、株価は、
- ノイズが多い
- レジーム(相場環境)が変わる
- 「昨日効いた特徴」が今日は効かない
という性質を持っています。
この不確実性に対抗するための最も実践的な手法がアンサンブル(Ensemble) です。
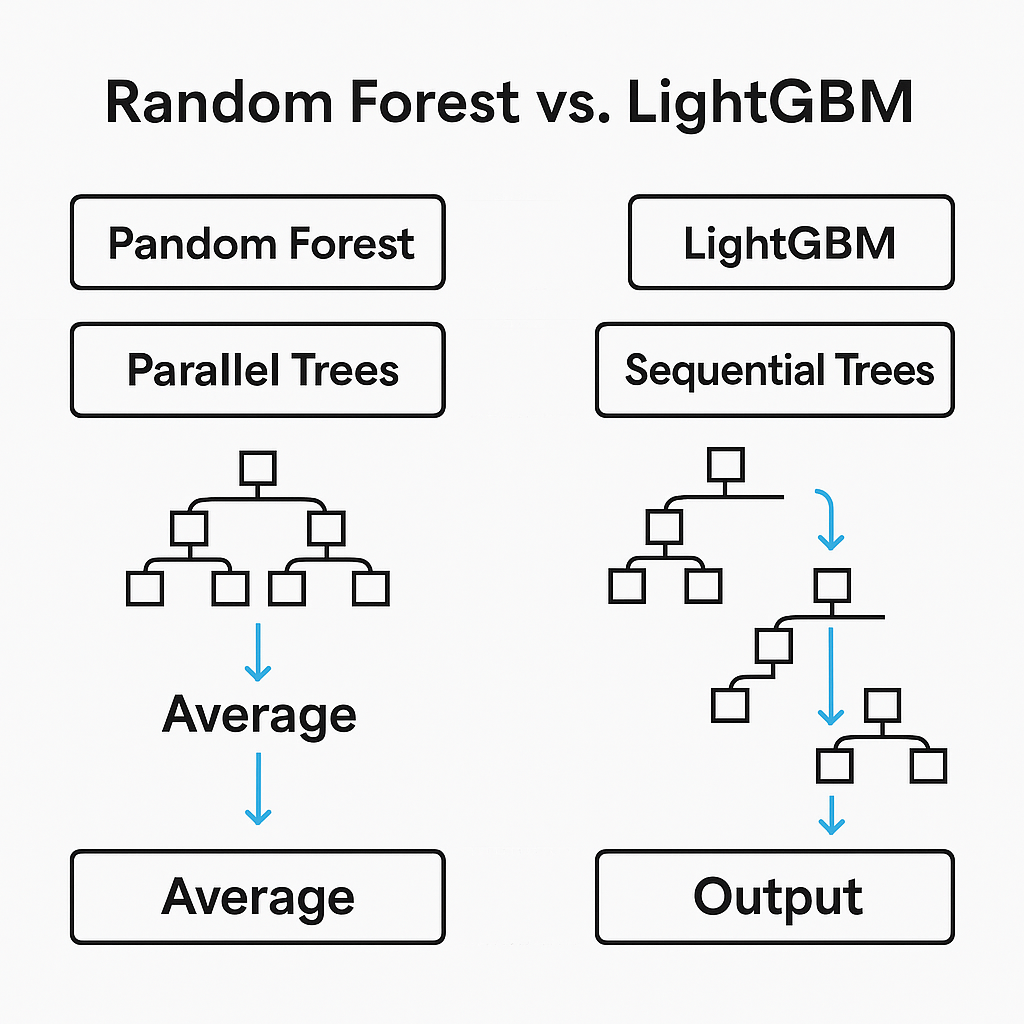
1.2 RandomForest × LightGBM の役割分担
今回実装するモデルは、
- RandomForest
- LightGBM(分位回帰 τ=0.5)
を組み合わせています。
RandomForestの役割(守り)
- 多数の木を平均する
- ノイズに強い
- 外れ値に引っ張られにくい
- 変化には鈍い
→ 「予測を安定させる役」(平均を取るため)
LightGBMの役割(攻め)
- 誤差を逐次修正
- 変化点に強い
- 非線形を鋭く捉える
- 過学習しやすい
→ 「相場の変化に反応する役」
重み 0.6 : 0.4 の意味
複数モデルを組み合わせて使う際、下式のように表現ができます。
上式の例だと、LGMBの方がRandomForestにたいしてやや重みがかかっています。
なぜ LightGBM をやや重くするのか
- 中央値回帰(τ=0.5)でノイズ耐性がある
- 変化点検出能力が高い
- 短中期の方向性を掴みやすい
なぜ RF を 0.4 残すのか
- 暴走防止
- CV分散の低減
- レジーム変化時の安全弁
👉 「LightGBMを信じるが、信じ切らない」
このバランス感覚が、実運用では極めて重要です。
H間スケール補正の考え方(3・5・10日予測)
今回実装予定のモデルは、複数の地平を同時に学習させる予定です。
例えば、
- H=3
- H=5
- H=10
という複数地平(予測ホライズン)を同時に学習しています。
なぜ地平ごとにモデルを分けるのか
株価の予測構造は、時間軸によって全く異なります。
| 地平 | 支配的要因 |
|---|---|
| 短期(〜3日) | モメンタム・出来高 |
| 中期(5日) | トレンド+調整 |
| やや長期(10日) | ボラ・方向性 |
単一Hでは、これらを同時に捉えられません。
H間スケール補正とは何か
補正は下式のように行います。
- H=3 → × (5/3)
- H=10 → × (5/10)
これは、
「対数リターンは期間に比例する」
という近似に基づいています。
厳密ではありませんが、
- ノイズが相殺される
- 方向性が揃う
- 短期・中期の情報を同時に使える
という実務的なメリットがあります。
Hブレンディングの思想
最終的にあなたは、
- H=5 を主
- H=3 を勢い補完(短期)
- H=10 を方向性補完(長期)
という構成にしています。
これは、
「今の勢い」と「全体の流れ」を同時に見る
という、人間トレーダーの判断を機械化した形です。
なぜ通常のCV(Cross Validation:交差検証)は使えないのか
時系列データでは、
- ランダムシャッフルCV
- K-fold CV
は 絶対に使用してはいけないです。
通常のCVは未来の情報が過去に漏れる
ローリング原点CVとは
ローリング原点CVでは、
- 学習データは常に「過去」
- テストデータは常に「未来」
という時間整合性を守ることができます。
ローリング原点CVの落とし穴
「CVがうまくいきすぎる」
CV結果が良すぎるとき、喜びすぎるのは危険です。
何かミスがないか疑ってみましょう。
- 特徴量リーク
- ターゲット平滑化の影響
- 相場レジームの偏り
エンバーゴの意味
エンバーゴとは、
学習期間とテスト期間の間に「空白」を設けること
です。
これにより、
- ラグ特徴量の漏洩
- 平滑化ターゲットの影響
- 近接期間の依存
を防げます。では具体的にどれくらい空白期間を設ければいいかですが、
学習期間がテスト期間の前日までに設定するのが最適だと思います。空白期間を長く設定してしまうと、テスト期間の直前情報が学習されないため、正確性が欠けると考えます。
ネストCVの重要性
ネストCVでは、
- 外側CV:真の汎化性能評価
- 内側CV:特徴量選択・ハイパラ調整
を分離します。
これにより、
「選んだ特徴量が未来でも効くか?」
を検証できます。
検証で見るべきは「平均」ではない
重要なのは、
- 平均値
- 標準偏差
- ワーストケース
です。
最後は、評価指標の解釈と運用KPIへの落とし込み方法について説明します。
MAEとは
MAE(Mean Absolute Error)は、
「平均して、何円ズレるか」
という指標です。
株価予測では最も直感的で、実務向きな指標です。
MAPEの意味と注意点
MAPEは「誤差が価格に対して何%か」を示す。
ただし、
- 価格が低いと過大評価
- ボラが高い局面で悪化
という特性があります。
MAE / ATR(Average True Range) が重要な理由
今回のモデルでは、MAE/ATR を導入します。
ATRとは、
「価格がどれくらい激しく動いているか(=ボラティリティ)」を測るための代表的な指標
です。
同じ「10円動いた」でも、
- 株価100円 → 激しい
- 株価2000円 → ほぼ誤差
ですよね。
ATRはその銘柄にとって「普通の値動きがどれくらいか」
を数値化します。
ATRが大きければ「動きが激しい」ことを意味します。
ここで、先ほど記載してMAEと組み合わせて、MAE/ATRという指標を導入することにしました。これは
「市場の揺れに対して、どれくらいズレたか」
を見る指標になります。
- MAE/ATR < 1 → 非常に良い
- 1<MAE/ATR<2 → 実用レベル
- 2<MAE/ATR → 危険
といって具合で判断できます。
HitRateをどう解釈するか
HitRate(方向一致率)は、
- 相場が一方向の時に過大評価
- 平滑化で上がりやすい
という問題があります。
👉 単独で使わない
👉 必ず MAE / ATR とセットで見る
モデルは「予言」ではなく「判断材料」
最も重要な考え方は、
モデルは未来を当てるものではない
ということを念頭におくことです。
モデルは、完璧に未来を当てられないため、
- 判断の偏りを減らす
- 感情を排除する
- リスクを定量化する
これらの要素を補完してくれる意思決定補助装置 だと思いましょう。
まとめ
- アンサンブルは「攻めと守り」の融合
- H間ブレンディングは人間の判断の模倣
- 検証は「厳しすぎるくらい」が正しい
これでモデル内で使用予定の項目をお伝えできましたので、次回はいよいよ株価予測の本番を実施してみます!













コメントを残す